Buenas prácticas en la creación de Tablas
La personas y los computadores ven las cosas de manera distinta, aunque para un investigador o grupo de investigadores una tabla pueda contener toda la información necesaria de una manera de fácil lectura, para los software los datos pueden ser difíciles de leer y se pueden cometer errores al intentar manejar y trabajar con los datos. A continuación te damos una serie de buenas prácticas y errores comunes que se comenten al momento crear y manejar tablas
- Ser consistente
Los datos no siempre son como se desean o se esta trabajando con datos en formatos que no son los ideales, lo importante es seguir una línea de trabajo y exploración. Si se cambian las metodologías de manera constante se crearan distintas tablas que luego serán difíciles de unir, manejar y compartir. Si se elige un tipo de tabla las demás deben seguir una estructura similar.
- Anticipar el uso de los datos
- Permite determinar de manera anticipada el formato que se va a necesitar y si es conveniente registrar los datos en algún estándar específico. Ahorrando tiempo en el procesamiento de los datos-
- Mantener registros de los cambios
- Crear archivos nuevos con las modificaciones y mantener el archivo original.
- Mantener un archivo de texto que registre los cambios que se han hecho a la base de datos.
- Preferir el manejo de datos a traves de scripts, así se puede mantener un registro de cuales fueron las acciones y se puede volver a repetir el proceso.
- Datos estructurados de manera rectangular
- Variables en columnas, observaciones en filas
- Una celda, un valor. No agrupar datos ( 30m, es preferible separar por valor y unidad de medida o establecer una condición para que en la columna se registre el valor en metros)
- La primera fila debería contener los nombres de las variables, evitar utilizar más de una fila para nombrar las variables
- Mantener los datos sin procesar. Es mejor generar otras tablas o documentos con valores como promedios, desviación estándar, mínimos, máximos. De esta manera se ayuda a no perder información y mantener un mejor orden de los análisis que se han realizado, además si se desean compartir los datos, es más útil compartir la totalidad de los datos para que otros investigadores puedan repetir u obtener nuevos resultados.
- Formato de tablas
- Wide, tidy, matrix: cada columna representa un valor para una variable. Preferida para aplicaciones estadísticas y es mejor cuando se describe con un archivo de metadatos ( por ejemplo EML)
- Long: pocas columnas, generalmente lugar, fecha y otra con el valor obtenido. Flexibilidad para añadir variables evitando celdas vacías
- Unir tablas
- Es recomendable mantener columnas iguales en datos de una misma medición para poder unir de manera más sencillas
- Es ideal diseñar las tablas para añadir solo filas, evitar añadir columnas.
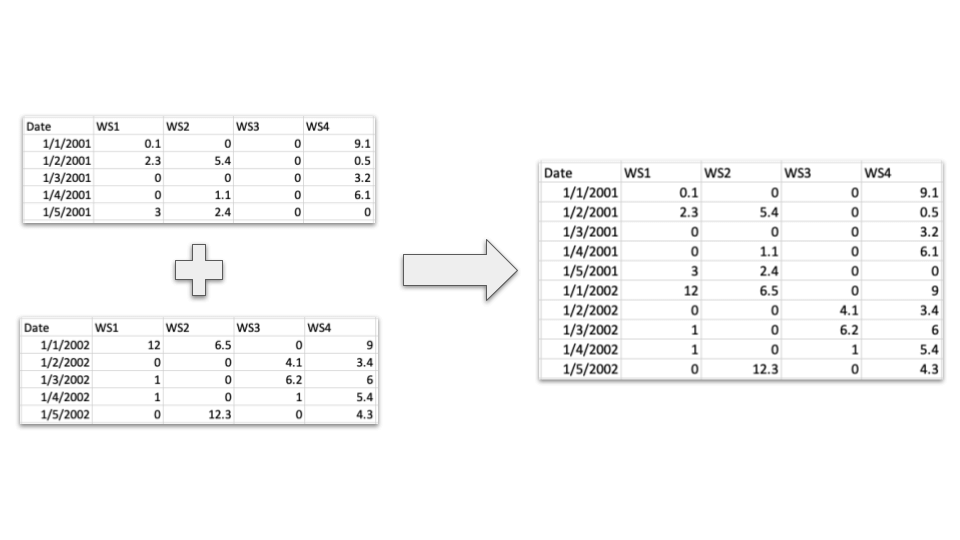
- Mediciones de distintas condiciones en un mismo sitio y día pueden unirse a generando columnas nuevas de cada condición
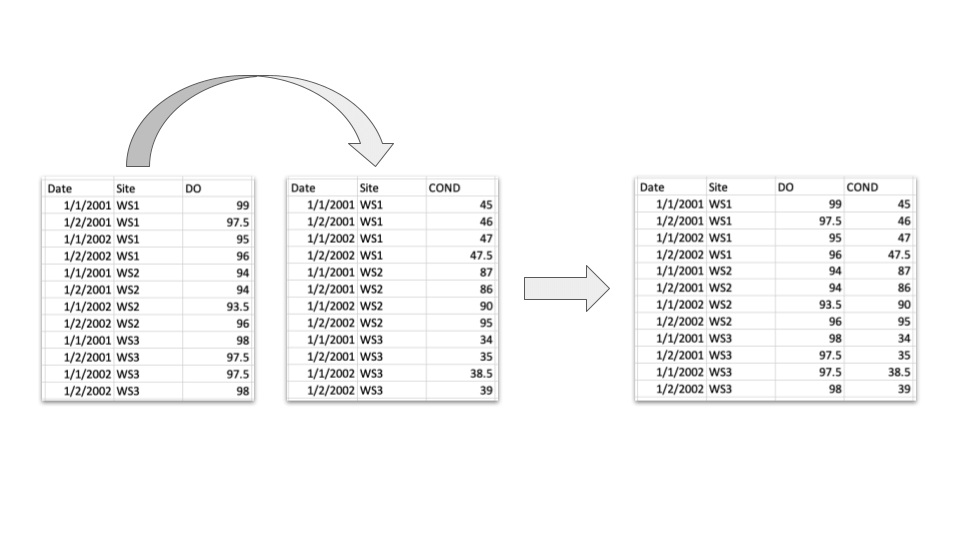
- Mediciones de una misma condición en sitios iguales, pueden agruparse según su fecha
- Tablas relacionadas o auxiliares
- Si los datos tienen información muy diferente y no se pueden unir, se puede usar distintas tablas en formatos predeterminados, como los archivos Darwin Core o los paquetes de datos ecocomDP, ambos son archivos comprimidos que constan de una tabla central que se complementa con tablas auxiliares.
- Si se están copiando datos en una variable que corresponde a solo una medición (precipitaciones, sitio, etc), es mejor crear tablas separadas para evitar la confusión sobre si solo es un descriptor o una variable medida.
- Registros únicos deben tener un identificador único, así es posible agrupar, comparar y analizar tablas diferentes a través de estos identificadores.
- Ventajas de usar tablas relacionadas
- Reducir celdas vacías
- Evitar cambios en la estructura de las tablas
- Reducir información y datos redundantes
- Hacer resúmenes más fácil
- Reducir inconsistencias
- Problemas en los formatos y como solucionarlos
- Usar tablas multiples en un mismo archivo
Es preferible crear otra variable que indique que son mediciones distintas o hacer archivos distintos para cada medición
- Usar hojas multiples
- Mayor posibilidad de añadir datos inconsistentes
- Mayor dificultad para exportar los datos
¿Es necesario hacer otra hoja o se puede crear una nueva variable?
- Usar valores nulos problemáticos
- Evitar 0 o cualquier otra variable numérica
- Evitar dar valor categórico (por ejemplo: no data, miss)
- Dejar valores nulos o incompletos como una celda en blanco (compatible con R, Python y SQL), o utilizar valor predeterminado por el software de análisis o estándar utilizado
- Usar las opciones de formato de la celda para expresar información
- No utilizar celdas resaltadas o distintos colores para entregar información (por ejemplo: outlier, error en la medición), esta información se debe almacenar como una nueva columna o variable.
- Uso de nombres problemáticos
- Se deben elegir nombres descriptivos, sin espacios ni caracteres especiales. Guiones bajos “_” son una buena alternativa para utilizar espacios. Considerar utilizar estilo de caja de camello (ejemploTitulo o EjemploTitutlo). Evitar abreviaciones o nombres largos. Evitar unidades de medida en los nombres.
- El nombre de la variable puede ayudar a indicar el tipo de valor que se almacena en esta
Nombre sugerido Alternativa Evitar Max_temp_C MaxTemp Maximum Temp (°C) Precipitation_mm Precipitation precmm Mean_year_growth MeanYearGrowth Mean growth/year sex sex M/F weight weight w. cell_type CellType Cell Type Observation_01 first_observation 1st Obs Sp1_Count Sp1 Sp. 1
- Usar tablas multiples en un mismo archivo
- Fechas como datos
- Es preferible guardar el AÑO,MES,DÍA en columnas distintas.
- Otra alternativa es guardarlo como AÑO, DÍA DEL AÑO
- Para guardarlo en una columna es preferible el formato YYYYMMDD
- Es recomendado también usar la fecha según el estándar ISO 8601 AAA-MM-DD hh:mm:ss, además de indicar la zona horario y las prácticas de observación de horario de verano durante las mediciones
- En ocasiones Excel no reconoce o tiene errores al registrar las fechas, esto se soluciona al utilizar un apóstrofe al inicio de la escritura (ejemplo: ‘2023-04-06 ), así excel reconoce como texto y evita que se transforme la fecha. Al guardar el archivo en formato .csv no se agrega dicho apóstrofe.
- Control de Calidad
- Utilizar sistemas de validación para evitar que se ingresen datos erróneos a las columnas
- Generar archivos readMe para conocer las transformaciones se han hecho a los datos
Plantilla archivo readMe Universidad Cornell
This readme file was generated on [YYYY-MM-DD] by [NAME] <help text in angle brackets should be deleted before finalizing your document> <[text in square brackets should be changed for your specific dataset]> GENERAL INFORMATION Title of Dataset: <provide at least two contacts> Author/Principal Investigator Information Name: ORCID: Institution: Address: Email: Author/Associate or Co-investigator Information Name: ORCID: Institution: Address: Email: Author/Alternate Contact Information Name: ORCID: Institution: Address: Email: Date of data collection: <provide single date, range, or approximate date; suggested format YYYY-MM-DD> Geographic location of data collection: <provide latitude, longiute, or city/region, State, Country> Information about funding sources that supported the collection of the data: SHARING/ACCESS INFORMATION Licenses/restrictions placed on the data: Links to publications that cite or use the data: Links to other publicly accessible locations of the data: Links/relationships to ancillary data sets: Was data derived from another source? If yes, list source(s): Recommended citation for this dataset: DATA & FILE OVERVIEW File List: <list all files (or folders, as appropriate for dataset organization) contained in the dataset, with a brief description> Relationship between files, if important: Additional related data collected that was not included in the current data package: Are there multiple versions of the dataset? If yes, name of file(s) that was updated: Why was the file updated? When was the file updated? METHODOLOGICAL INFORMATION Description of methods used for collection/generation of data: <include links or references to publications or other documentation containing experimental design or protocols used in data collection> Methods for processing the data: <describe how the submitted data were generated from the raw or collected data> Instrument- or software-specific information needed to interpret the data: <include full name and version of software, and any necessary packages or libraries needed to run scripts> Standards and calibration information, if appropriate: Environmental/experimental conditions: Describe any quality-assurance procedures performed on the data: People involved with sample collection, processing, analysis and/or submission: DATA-SPECIFIC INFORMATION FOR: [FILENAME] <repeat this section for each dataset, folder or file, as appropriate> Number of variables: Number of cases/rows: Variable List: <list variable name(s), description(s), unit(s) and value labels as appropriate for each> Missing data codes: <list code/symbol and definition> Specialized formats or other abbreviations used:
- Buscar errores en los valores que puedan estar escondidos debido a ciertos filtros o clasificaciones (datos erróneos se ubican de manera general al final de las tablas)
- Comprobar valores
- Registros duplicados: listados dos veces, pero no réplicas
- Registros secuenciales: comprobar que esta en la correcta secuencia
- Rangos: si hay muchos datos fuera de rango puede indicar error en la medición
- Persistencia: datos constantes puede indicar mediciones erróneas
- Cambio en la pendiente y escalones: en series de tiempo, puede representar una desviación en el instrumento
- Consistencia interna: Los valores se encuentran dentro de un rango establecido según el sitio de muestreo
- Consistencia en pareja: Observadores/instrumentos duplicados producen valores y tendencias similares
- Crear un diccionario de datos
- Los nombres exactos de las variables de cada archivo
- Una versión de el nombre de la variable que puede ser utilizada en la visualización de los datos
- Explicaciones más extensas del significado de cada variable
- Valores mínimos y máximos esperados
- Exportando los datos
- Formatos como .xlsx pueden tener errores ya que guardan formatos que no son legibles por otros softwares y es un formato que no todas las revistas o repositorios aceptan.
- Exportar los datos en csv o en formato plano de texto. Estos formatos son compatibles con la mayoría de los software pueden leer este tipo de archivos, se pierde menos información por el cambio de formato y los repositorios de manera general sugieren este formato al momento de compartir datos
- Nombre de los archivos
- Se sugiere usar nombres cortos, sin caracteres numéricos ni especiales, sin espacios (utilizar guion bajo “_”, o formato caja camello)
- Idealmente el nombre del archivo debe tener indicios de el lugar, tiempo y tema, incluso si debe estar abreviado.
Nombre de archivo no recomendado: soil properties 2010-2020.csv
Nombre de archivo recomendado soil_properties.csv
Nombre de variable no recomendado: dissolved oxygen % saturation
Nombre de archivo recomendado dosat
- Crear y mantener actualizado un archivo de metadatos o readMe
- Permite tener las información del qué, como, cuándo, donde y quién de la información presentada
- Util en el caso de tener multiples versiones o tablas combinadas
- Existen diversos formatos, pero lo importante es que sea descriptivo y complemente la información de que se entregan en las tablas
- Se puede añadir el diccionario de los datos.
- Crear respaldos
- Ideal es seguir la regla de tres: TRES copias, al menos en DOS formatos distintos, con una copia en un lugar distinto (universidad, computador, servidor)
- Mantener el archivo original, sin correcciones y en formato de solo lectura.
- Mantener todas las versiones de los archivos mientras se trabajo, así, en caso de que exista un pérdida se puede recuperar información
- Cuando se finalice el trabajo con los datos, proteger los datos cambiando la configuración a solo lectura
Referencias
Borer, E.T., Seabloom, E.W., Jones, M.B. and Schildhauer, M. (2009), Some Simple Guidelines for Effective Data Management. The Bulletin of the Ecological Society of America, 90: 205-214. https://doi.org/10.1890/0012-9623-90.2.205
White EP, Baldridge E, Brym ZT, Locey KJ, McGlinn DJ, Supp SR. 2013. Nine simple ways to make it easier to (re)use your data. PeerJ PrePrints 1:e7v2 https://doi.org/10.7287/peerj.preprints.7v2
Hart EM, Barmby P, LeBauer D, Michonneau F, Mount S, Mulrooney P, et al. (2016) Ten Simple Rules for Digital Data Storage. PLoS Comput Biol 12(10): e1005097. https://doi.org/10.1371/journal.pcbi.1005097
Karl W. Broman & Kara H. Woo (2018) Data Organization in Spreadsheets, The American Statistician, 72:1, 2-10, DOI: 10.1080/00031305.2017.1375989
Data Organization in spreadsheets for ecologists. Available at: https://datacarpentry.org/spreadsheet-ecology-lesson/ (Accessed: April 6, 2023).
Peter R. Hoyt, Christie Bahlai, Tracy K. Teal (Eds.), Erin Alison Becker, Aleksandra Pawlik, Peter Hoyt, Francois Michonneau, Christie Bahlai, Toby Reiter, et al. (2019, July 5). datacarpentry/spreadsheet-ecology-lesson: Data Carpentry: Data Organization in Spreadsheets for Ecologists, June 2019 (Version v2019.06.2). Zenodo. http://doi.org/10.5281/zenodo.3269869
O'Brien, M., Smith, C. A., Sokol, E. R., Gries, C., Lany, N., Record, S. and M. C. N. Castorani. 2021. "ecocomDP: A flexible data design pattern for ecological community survey data." Ecological Informatics 64:101374. DOI: https://doi.org/10.1016/j.ecoinf.2021.101374
Cornell University. Author_dataset_readmetemplate.TXT: Powered by Box. Available at: https://cornell.app.box.com/v/ReadmeTemplate (Accessed: April 6, 2023).
Cornell University (2022) . Research Data Management Service Groupcomprehensive Data Management Planning & Services. Data storage and backup | Research Data Management Service Group. Available at: https://data.research.cornell.edu/content/data-storage-and-backup (Accessed: April 6, 2023).
Cornell University (2022). Research Data Management Service Groupcomprehensive Data Management Planning & Services (no date) Metadata and describing data | Research Data Management Service Group. Available at: https://data.research.cornell.edu/content/writing-metadata (Accessed: April 6, 2023).