¿ Qué es GBIF y qué información puedo obtener?
¿Qué es GBIF?
GBIF es la sigla para Global Biodiversity Information Facility (Infraestructura Mundial de Información en Biodiversidad). En palabras simples, es una plataforma que recopila información sobre especies y su distribución en el mundo de manera sistematizada, ya sea a través de Check-list de especies, registros en eventos de muestreos o registros biológicos.
En GBIF puedes encontrar información tanto registros realizados de manera in-situ, al igual de registros de colecciones de museos.
Muchos países están asociados a GBIF y están comprometidos con colaborar en el acceso a la información relacionada con la Biodiversidad, permitiendo que distintas entidades publiquen a través de plataformas gubernamentales o relacionadas a instituciones de investigación. En caso de BASE, existe el acceso a publicar a través de GBIF Chile.
GBIF esta conectada con la plataforma INaturalist, así los registros subidos a esa plataforma también son registrados en GBIF.
Toda la información registrada en GBIF se encuentra en archivos de tipo Darwin Core
¿Qué es un archivo Darwin Core (DwC-A)?
Un archivo Darwin Core (DwC-A) se compone generalmente de tres tipos de archivos:
- Archivo core (obligatorio): este corresponde a los datos que serán registrados (puedes revisarlos en la siguiente sección). Estos deben complir con el estandar Darwin Core, en manera simple, es un sistema de parámetros establecidos que deben tener los datos, por ejemplo, en lugar que la tabla con los registros diga “ESPECIE” , para identificar el nombre científico la columna tiene que tener por nombre “scientificName”. Aunque es posible tener nombre de columnas u otros descriptores en tus datos de manera personalizada y posteriormente cambiar el nombre de manera manual al publicar (mapear los datos DwC), la mejor práctica es utilizar de manera directa el estándar DwC, en la siguiente sección podrás ver cuales son los parámetros obligatorios y sugeridos que deben tener tus plantillas, con links externos para explorar que significa cada término, además de planillas para utilizar y ejemplos. Además puedes encontrar la planilla BASE para la publicación de registros biológicos.
- Archivo extensión (opcional): archivos que complementen la información que se registra en el archivo core, este también debe estar en formato DwC y tiene que estar identificado a que registro hace referencia del archivo core, un ejemplo puede ser una lista de nombres comunes para las especies registradas en un evento de muestreo.
- Meta-archivo descriptor (obligatorio): Es un archivo que describe los datos del core y de la extensión. Este es un archivo XML simple que se puede crear de manera directa en la plataforma GBIF, y describe que campo DwC está en cada columna.
- Metadatos del recurso (obligatorio): Un metadato es información sobre los datos (datos sobre datos), este contiene información de los autores, métodos de muestreo empleados, entre otra información. Esta se puede completar a través de la plataforma GBIF.
¿Cómo obtengo datos desde GBIF?
La consulta de datos más recurrente en GBIF es los datos de ocurrencia de especies o taxones específicos. Para poder obtenerlos existen diversas instancias donde puedes descargar
- Desde la página de gbif
- A través del API gbif
- Con programas externos como R o Python
Es importante tener en consideración que para poder descargar y usar los datos debes tener una cuenta GBIF (la cuál puedes crear con cualquier correo electrónico) y si deseas utilizar esos datos para investigación o cualquier documento con objetivos de publicar debes citar correctamente tus descargas.
GBIF recomienda el uso del paquete rgbif para descargar datos de ocurrencias, a continuación se explica como utilizar este paquete utilizando RStudio
- Instalación de los paquetes
setwd("C:/R/GBIF") #seleccionar carpeta de trabajo
install.packages("rgbif") #instalar paquete rgibf
library(rgbif) #activar paquete
install.packages("usethis") #paquete para instalar credenciales
library(usethis)
usethis::edit_r_environ() #esto abrira otra pestaña para que puedas activar las credenciales- Activar credenciales
Aquí debes poner las credenciales con las que estas registrado en GBIF, en primer lugar puede que solo aparezca la consola vacía, ahí debes ingresar tus credenciales siguiendo el ejemplo, no olvides reeiniciar R para que se guarden los cambios
GBIF_USER="nombredeusuario" GBIF_PWD="contraseña" GBIF_EMAIL="correo@gbif.cl"
- Identificar el taxón
Para poder identificar a que taxon del cual vas a hacer la consulta es necesario que conozcas su taxonKey que corresponde a un número con el cual se registra en GBIF. Para hacerlo puedes buscarlo de manera directa en la página de GBIF, corresponde al número al que aparece al final de URL cuando se busca una especie
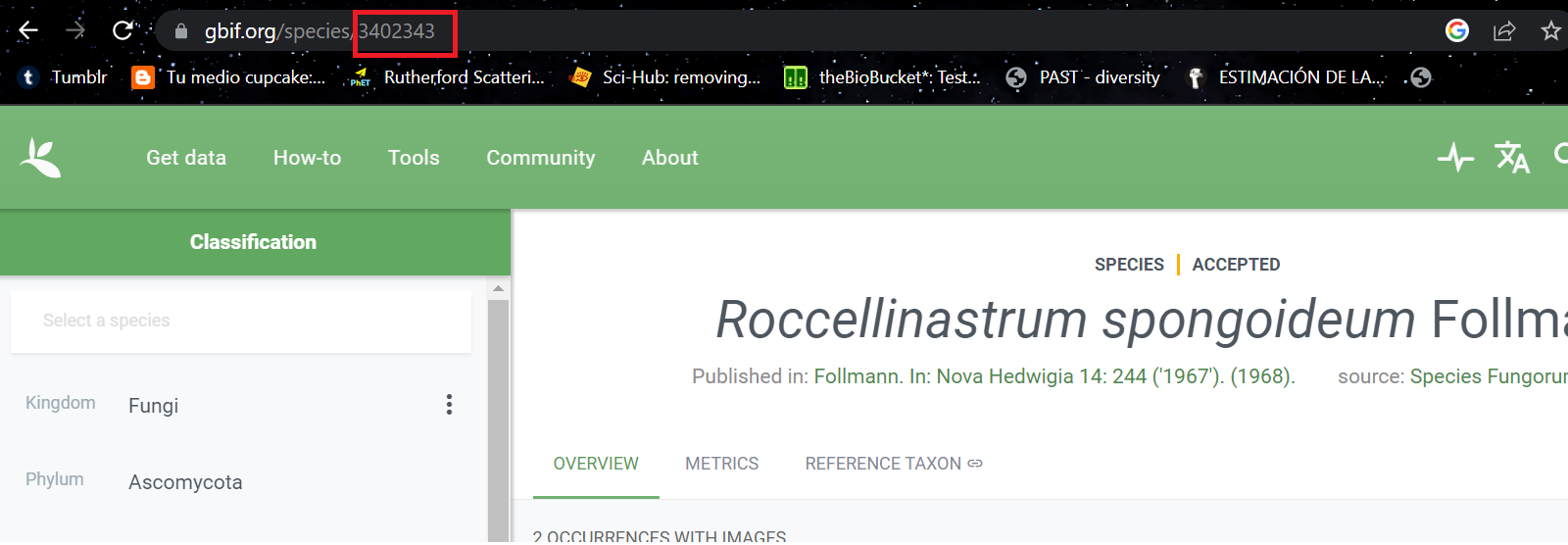
También puedes hacer la consulta a través de R siguiendo el siguiente código
name_backbone("Roccellinastrum spongoideum")$usageKey #nombre del taxón que se desea consultar
- Realizar la solicitud de descarga
Para realizar descargas de los datos es necesario hacer solicitudes específicas sobre le taxón requerido, es importante que si los datos serán utilizados en estudios se utilice occ_download. Es posible realizar varios filtros de manera directa al iniciar la descarga, a continuación está un ejemplo de descarga con filtros básicos y otra con filtros más avanzados
#descargasimple gbif_download2<-occ_download( pred("taxonKey", 3402343), #especificar el taxón pred("hasGeospatialIssue", FALSE),#elimina errores geoespaciales predeterminados pred("hasCoordinate", TRUE),#solo registros con coordenadas pred("occurrenceStatus","PRESENT"), #eliminar registros ausentes pred_not(pred_in("basisOfRecord",c("FOSSIL_SPECIMEN","LIVING_SPECIMEN"))), format = "SIMPLE_CSV" ) #eliminar especímenes fosilis y vivos occ_download_wait(gbif_download2) #consulta del tiempo de espera d2 <- occ_download_get(gbif_download2) %>% occ_download_import() #importar la descarga a objeto en R #descarga compleja gbif_download3<-occ_download( type="and", pred("taxonKey", 2436775), pred("hasGeospatialIssue", FALSE),#elimina errores geospaciales predeterminados pred("hasCoordinate", TRUE),#solo registros con coordenadas pred("occurrenceStatus","PRESENT"), #elimina registros ausentes pred_gte("year", 1900),#después de/o año 1900 pred_not(pred_in("basisOfRecord",c("FOSSIL_SPECIMEN","LIVING_SPECIMEN"))), #elimina especímenes fósiles y vivos pred_or( pred("country","ZA"), pred("gadm","ETH") ),#en sudáfrica o etiopia usando polígonos distintos pred_or( pred_not(pred_in("establishmentMeans",c("MANAGED","INTRODUCED"))), pred_isnull("establishmentMeans") ),#la columna estabilshmentMeans no contiene especies gestionadas o introducidas, pero se pueden dejar en blanco pred_or( pred_lt("coordinateUncertaintyInMeters",10000), pred_isnull("coordinateUncertaintyInMeters") ),#coordinateUncertaintyInMeters es menor a 10K metros o es dejado en blanco format = "SIMPLE_CSV" ) d3 <- occ_download_get(gbif_download3) %>% occ_download_import() #importar la descarga a objeto en R
Para pasar los archivos de objetos a un archivo excel puedes ocupar la función write.csv() o lo que estimes conveniente.
Pueden encontrar más información y otros comandos en el repositorio oficial de rgbif en el siguiente enlace:
También puedes descargar el script para R a continuación o descargarlo del repositorio Github de IBASE